
9.8. Effect Size, Power, and Sample Size Selection#
This section considers one aspect of experimental design: how to select the sample size for an experiment. That value will depend on characteristics of the underlying data (which are at least partially unknown) and on performance criteria, including the acceptable probabilities of Type I and Type II errors.
We consider only sample size selection for the case of testing a difference of means between two populations with standard deviations that are equal and known. In particular, consider two populations with (unknown) means \(\mu_X\) and \(\mu_Y\), respectively, and common (but unknown) standard deviation \(\sigma\). Suppose we observe \(n_X\) random values \(\mathbf{X} = \left[ X_0, X_1, \ldots, X_{n_X-1} \right]\) and \(n_Y\) random values \(\mathbf{Y} = \left[ Y_0, Y_1, \ldots, Y_{n_Y-1} \right]\) from these two distributions. Let \(\hat{\mu}_X\) and \(\hat{\mu}_Y\) be the mean estimators that are computed from \(\mathbf{X}\) and \(\mathbf{Y}\). By the Central Limit Theorem, if \(n_X\) and \(n_Y\) are sufficiently large (at least 10), then \(\hat{\mu}_X\) and \(\hat{\mu}_Y\) can be modeled as Normal random variables such that
Let \(T\) be a test statistic for a difference of means, where \(T = \hat{\mu}_X -\hat{\mu}_Y\). Then our previous results show that
For convenience, let
Under \(H_0\), \(T \sim \mbox{Normal}\left(0, \sigma_T \right)\). A Type I error is rejecting \(H_0\) when it is true. I will present the analysis for a one-sided test because it results in a straightforward analysis that can be easily solved without approximation for one special case. I will also present the final result for a two-sided test, along with an approximation that makes it easier to solve. We will consider the one-sided test for \(\mu_X > \mu_Y\), under which \(H_0\) will be rejected if \(T\) is much larger than 0; i.e., \(T>\gamma\) for some threshold \(\gamma\). Then
Note, however, that this probability depends on \(\sigma_T\), which depends \(n_X\) and \(n_Y\). Since \(n_X\) and \(n_Y\) are sample sizes that we wish to choose, this may seem like we are going in circles. However, we will find that we can put this together with other information to determine the necessary sample sizes.
Let the acceptable probability of Type I error be denoted by \(\alpha\). Then we can solve for the threshold \(\gamma\) as
Now consider the probability of Type II error, which is the probability of failing to reject the \(H_0\) when \(H_a\) is true. Let \(\beta\) denote the acceptable probability of Type II error. Usually, the value of \(\beta\) is not specified directly; instead, the power of the test is specified, which is \(1-\beta\). A typical target value for statistical power is 80%, but higher values are sometimes used.
Under \(H_a\), the expected value of \(T\) is \(\mu_a- \mu_b\), which is greater than zero for our one-sided test. Then a visualization of \(P(T \leq \gamma)\) is shown below.
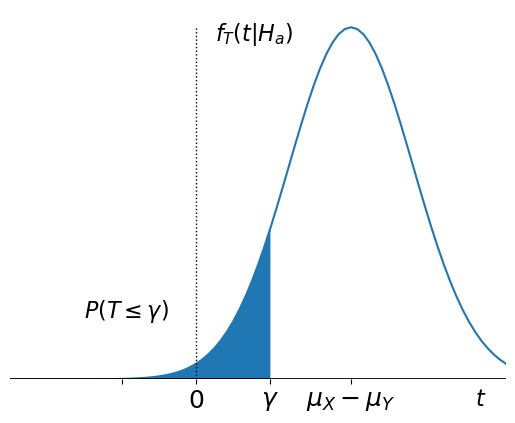
Then we can express the probability of Type II error as
Setting this equal to \(\beta\) and solving for \(\gamma\) yields
Combining this with the result for Type I error, we have
Substituting the value for \(\sigma_T\) yields
Let
be Cohen’s \(d\), which is a type of effect size:
DEFINITION
- effect size #
One of many measures of separation between distributions. For a difference of means, Cohen’s \(d\) is standard:
\[\begin{equation*} d =\frac{\mu_X - \mu_Y}{\sigma}. \end{equation*}\]
Cohen’s \(d\) is the normalized difference in the means between the two groups. In practice, the effect size is not known before the experiment, but it is often practical to make some assumption about the effect size. We can either use information from other studies to estimate the effect size, or for intervention tests (for instance, medical drugs), the intervention may only be worth pursuing if it has a significant effect compared to no intervention. Effect sizes are also often specified by descriptors, which are adjectives that indicate the relative effect size and which have been specified in the statistics literature according to the table below.
Cohen’s \(d\) |
Effect size descriptor |
|---|---|
0.01 |
Very small |
0.2 |
Small |
0.5 |
Medium |
0.8 |
Large |
1.2 |
Very large |
2.0 |
Huge |
Using the definition of Cohen’s \(d\) and reorganizing the equation yields the following relation that can be solved for \(n_X\) and \(n_Y\) in terms of \(\alpha\), \(\beta\), and \(d\),
In general, multiple possible solutions can be found using a computer. If we consider equal sample sizes, \(n_X = n_Y\), then the formula simplifies to
A function to calculate the size of two equal-sized groups given the values of the significance level (\(\alpha\)), power (\(1-\beta\)), and the effect size (\(d\)) is below:
from scipy import stats
def qinv(x):
return stats.norm.isf(x)
def group_size_1sided(significance, power, effect_size):
return 2*(qinv(significance) +
qinv(1-power)) **2 /(effect_size)**2
For example, for a statistical significance of 0.05, power of 0.8, and effect size of 0.8, the size of each group should be at least
group_size_1sided(0.05, 0.8, 0.8)
19.32049135006178
Since we cannot use fractionally sized groups, we will generally have to round up to the next largest integer, so groups of size 20 will be required, for 40 total participants.
Let’s test this result for a simple data set, where the groups come from uniform distributions on intervals of length 10. Let the random variables that the data from the two groups be denoted by \(X\) and \(Y\), respectively. Let \(Y\) represent the data from our control group and assume \(Y \sim\) Uniform[0,10].
To evaluate the probability of false alarm and the probability of miss, we have to create two different distributions for \(X\):
When \(H_0\) is true, then \(X\) should have the same distribution as \(Y\). Let
X0have distribution \([0,10]\).When \(H_a\) is true, then \(X\) should have a distribution that differs from \(Y\) at some effect size. Assuming a “Large” effect size, the normalized mean of \(X\) should differ from the mean of \(Y\) by 0.8. Thus, let
X1have distribution that is shifted by \(0.8 \sigma\), where \(\sigma\) is the standard deviation of a uniform random variable on an interval of length 10.
X0 = stats.uniform(loc=0, scale=10)
stdX=X0.std()
stdX
2.8867513459481287
Then the interval should be shifted by
0.8*stdX
2.309401076758503
X1 = stats.uniform(loc=2.31, scale=10)
Y = stats.uniform(loc=0, scale =10)
Y.std()
2.8867513459481287
Since we are assuming that the standard deviation of the distributions is known, we can calculate the threshold \(\gamma\) based on the significance \(\alpha=0.05\) as
If \(\sigma\) is the original standard deviation, then
Then the threshold \(\gamma\) is
import numpy as np
n=20
gamma = stdX*np.sqrt(2/n) * qinv(0.05)
gamma
1.501539058792515
# Run a simulation to determine achieved alpha
num_sims = 10_000
count = 0
for sim in range(num_sims):
x = X0.rvs(n)
y = Y.rvs(n)
t = x.mean() - y.mean()
if t >= gamma:
count += 1
print(count/num_sims)
0.0492
# Run a simulation to determine achieved beta
num_sims = 10_000
count = 0
for sim in range(num_sims):
x = X1.rvs(n)
y = Y.rvs(n)
t = x.mean() - y.mean()
if t < gamma:
count += 1
print(count/num_sims)
0.1912
The achieved \(\alpha\) and \(\beta\) are very close to the target values, even though the actual sampling distribution of \(\hat{\mu}_X\) and \(\hat{\mu}_Y\) will not be exactly Normal.
Note that the smaller the effect size, the larger the groups must be. For instance, if the effect size is only \(d=0.2\), the required group sizes for \(\alpha=0.05\) and \(\mbox{power}=0.8\) are
group_size_1sided(0.05, 0.8, 0.2)
309.12786160098847
Although we may be able to obtain statistical significance with such large groups, the meaningfulness of that result may be reduced because the two groups are not very different from each other in terms of their means relative to their standard deviations.
Two-Sided Tests
For a two-sided NHST, the values of \(n_X\) and \(n_y\) must satisfy
The form of the second equation prevents us from solving for \(\gamma\), but the second term in that equation is usually much, much smaller than the first term and thus can be neglected. After simplification, we get a form that is almost identical to the result for a one-sided test:
which for equal group sizes simplifies to
A function to calculate group sizes for the two-sided test is below:
def group_size_2sided(significance, power, effect_size):
return 2*(qinv(significance/2) +
qinv(1-power)) **2 /(effect_size)**2
For example, for the two-sided test with significance level \(\alpha=0.05\), power \(1-\beta = 0.8\), and effect size \(d=0.8\), the necessary group sizes are
group_size_2sided(0.05, 0.8, 0.8)
24.527749169840906
For more general cases of determining group sizes, such as unequal group sizes and unknown or unequal standard deviations among the groups, the statsmodels.stats.power library provides a variety of functions to calculate necessary group sizes.
Thus, power and effect size can be combined with the statistical significance threshold to estimate the number of participants that will be needed for an experiment.
9.8.1. Terminology Review#
Use the flashcards below to help you review the terminology introduced in this chapter. \(~~~~ ~~~~ ~~~~\)